
Differential ETL | Part 1
"bring compute to the data"


This is a two-part series about an exciting area of work at hotg.ai. The second part will be a follow up post in a week.
In the first part we want to touch upon a familiar concept of distributed map reduce but with a few twists.
If you are wondering how this relates to the world of edge computing - read on :).
A brief primer
The classic paper from Google that introduced us to the world of map reduce pattern in 2004 was designed to address computing on large data where the computations need to be distributed across hundreds or thousands of machines to finish in a reasonable amount of time.

source: google map reduce paper
To simply put, you have a large data set in a central location that needs to be processed with well-defined computation that can be parallelized over a network of compute nodes. The mapped results are then reduced, again with a well-defined computation to a meaningful result.
This is a distributed computing implementation of the well-known MapReduce design pattern.
A well-known variation of this is using streaming data (Spark) as opposed to batch processing (Hadoop).
The conundrum of centralizing data
Every modern enterprise is creating new data across several touch points within the organization. This could be data created in ERP systems, sales systems, product systems, application data, monitoring data, vendor data, infrastructure, and much more.
ELT helps enterprises bring all raw data in a Data Lake, allowing them to build more refined datasets in a Data Warehouse. In return, the Data Warehouse becomes useful for downstream systems such as machine learning systems and analytics systems.
a16z has written what a modern enterprise’s unified data platform could look like.
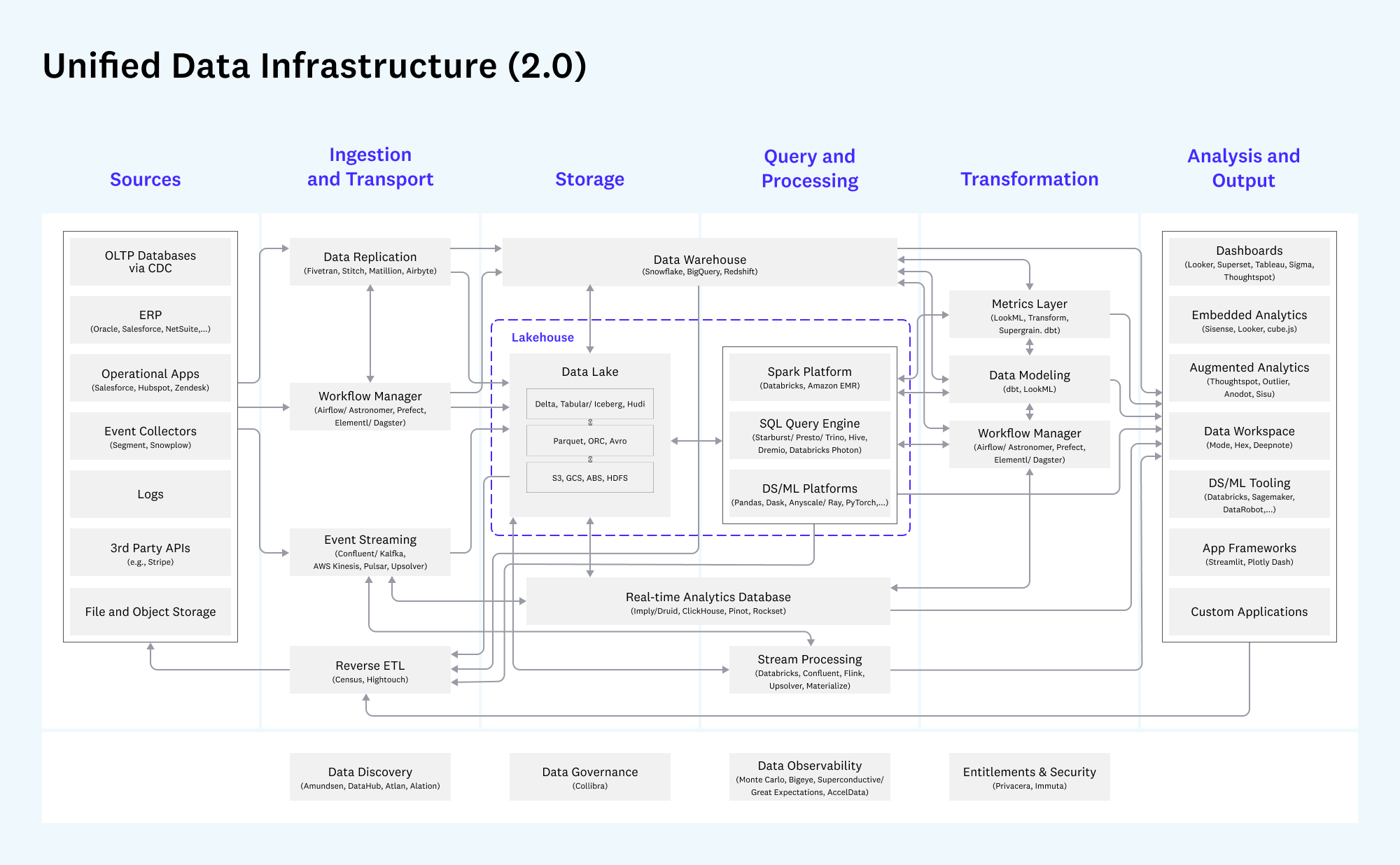
source: https://future.a16z.com/emerging-architectures-modern-data-infrastructure/
There are hundreds of companies working in the “ETL space” that are iterating on ways to help enterprise centralize their data. a16z has a brief list as well.
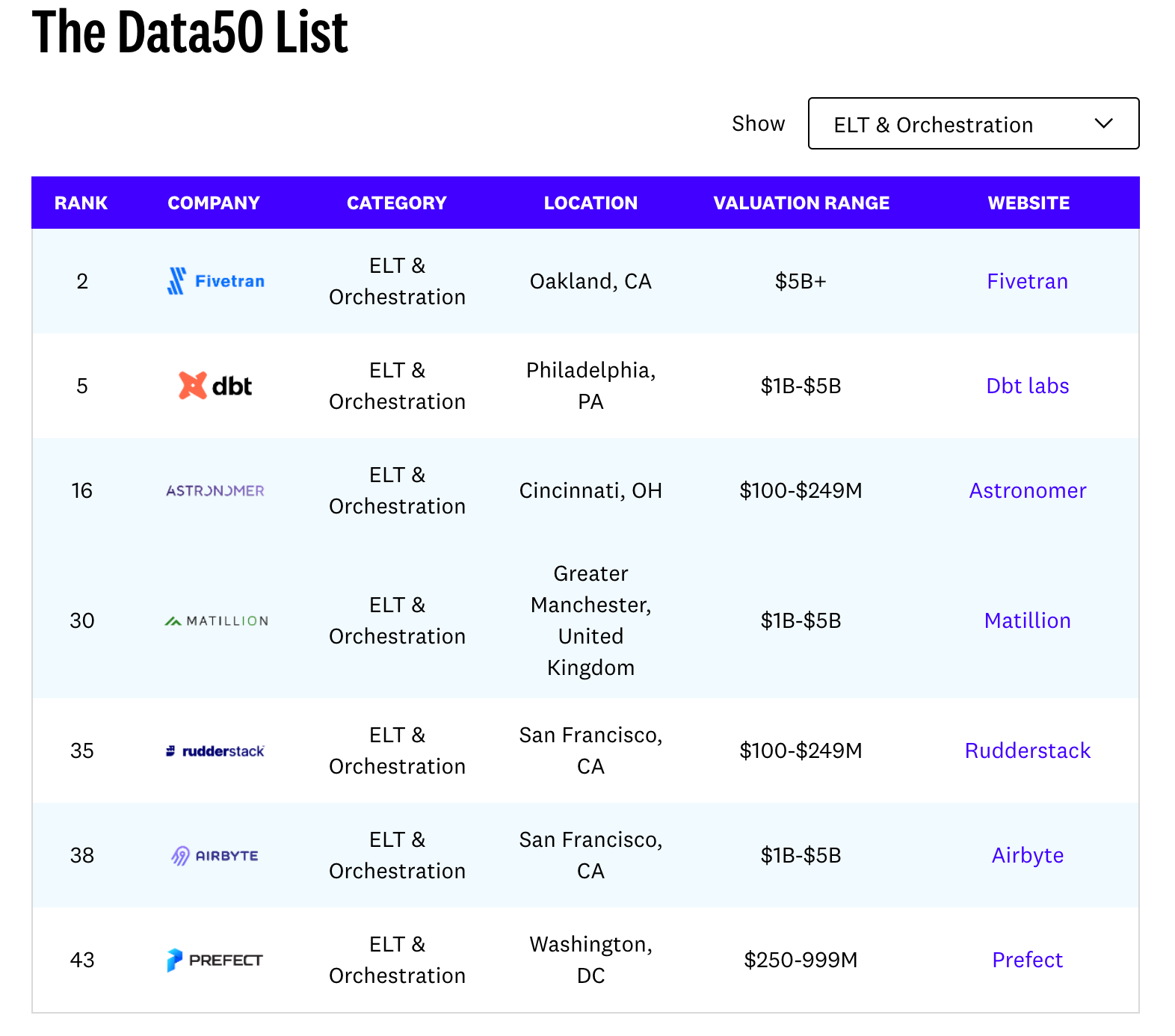
source: https://future.a16z.com/emerging-architectures-modern-data-infrastructure/
If you are an enterprise, the goal to centralize ALL data in one place is an asymptote - it will be a never-ending catch-up game.
This leads to the conundrum:
What if you cannot centralize all the data?
A fragmented and distributed world

With most enterprises, there’s massive fragmentation of data that is accumulating in small silos that cannot easily centralize. Here are some key reasons as to why this is the case:
Compliance and privacy - GDPR, CCPA, and every state, country, and region are moving towards creating unique laws around how citizen’s data should be handled
Rapid rate at which new type of data is added - creating and maintaining new data ingestion is an expensive endeavor
Security is a priority - sometimes, it is about permanent control on access to data for regulatory reasons
Heterogeneity in where the data is generated and kept - a lot of times the data is sent via email, spreadsheets, FTP files, a local database, and so on. Places where you can forget about running a spark job.
From our point of view, the future of fragmentation looks something like this:
We will need to bring the compute to data
The data will not only be spread in data silos internally, but it will also be on user devices, across partners, and hybrid cloud and on-prem.
Embracing heterogeneous computing will become paramount for the success of an enterprise.
What will be even more interesting is that not only will each data silo look different, but it will also contain different fragments of data.
This means you cannot easily apply MapReduce patterns to gain computational advantages easily
We will have to bring compute to hostile environments that might have extremely limited capabilities. For instance, phones, bare metal computer running in a basement at a hospital, an on-prem data center VM, multiple cloud environments each with its own setup, and so on.

We call this “Differential ETL”
You could run different workloads in each silo, and still need to reduce the output of each node. Think of it as not trying to bring the data to one place but bringing the insights from the data to wherever needed.
We want to be clear in stating that centralizing the data with ETL technologies will continue to exist and grow, but there will also be a higher rate of fragmentation.
There is no easy way to run docker on these systems:

Part 2 | Prologue
Hopefully, we have whet your appetite for data fragmentation across a heterogeneous platform. We call moving compute to where the data silo is a problem of edge computing.
In part two of this series, we will go a bit deeper on the examples and use cases of differential ETL across a few industries. We will also couple that with some sneak peaks into some exciting work we have been doing in this space with our Rune container technology :)
Until then, keep building the future!
HOT-G Socials:
Twitter @hotg_ai and @hammer_otg | LinkedIn | Discord