
Rune-ifying Audio Models
Bringing audio models to the edge with Runes

Overview
When you think of what docker did to the world of cloud computing, it is remarkable. Amazon defines docker as:
Using Docker, you can quickly deploy and scale applications into any environment and know your code will run. You can do this because Docker packages software into standardized units called containers that have everything the software needs to run including libraries, system tools, code, and runtime.
Containerization on the cloud changed the game for how we defined and build software. Any compute could be reliably shipped to complex changing infrastructure.

Containerization led to new complexity on the cloud with micro-services which was then addressed by Kubernetes.
Kubernetes, also known as K8s, is an open-source system for automating deployment, scaling, and management of containerized applications.
Today we live in a world where cloud deployments are mostly a solved problem. Developers think in terms of computations, containerization, and orchestration.
This is completely missing in the world of edge computing and tinyML.
In our previous post we presented what HOTG’s mission is for the next several years:
HOTG is building the distributed infrastructure to pave the way for AI enabled edge applications
Today marks another step in that direction.
Bringing audio models to the edge
We aim to be your one-stop-shop for easily deploying machine learning models to various devices. Instead of long setup on various devices, we are building the technology to easily package your models into runes and deploy them to multiple devices.
To meet this aim, we are ramping up the development of our technologies and working on expanding types of models we can support. We started off by building a repository of Image classification models - Checkout our Mobile Application on iOS and Android. Our current focus is on creating runes using audio models.
Exploring Audio Models
TensorFlow Hub holds a large repository of easily accessible audio models. These can be classified into 3 different types.
Event Extraction
Speech Synthesis - Various GAN models
Audio embedding
Each of these models can offer many interesting use cases. For example, Event extraction can help us determine sounds that are occurring in the environment. Speech synthesis models can convert audio to a textual format. Finally, audio embedding models can convert audio to word embeddings which can help in downstream Natural Language Processing tasks.
Something interesting we noticed with many TensorFlow Lite audio models is that they may have multiple inputs and/or multiple outputs. This is unlike Image Classification models which were mostly observed to have a single input (the image in question) and a single output (a probability vector corresponding to a label).
For instance, the structure of a YAMNet model (an audio event classifier) is such that it contains 1 Input and 3 Outputs. We can observe further details using the rune-cli tool.
$ rune model-info yamnet.tfliteOps: 114
Inputs:
# Audio Input
waveform: Float32[1]
Outputs:
# Probability vector which can be mapped to a label representing the audio event
Identity: Float32[1, 521]
# Average pooled output which feeds into the final classification layer
Identity_1: Float32[1, 1024]
# log mel spectogram of the Audio Input
Identity_2: Float32[1, 64] 
P.S - you can use the Rune CLI tools to inspect any model and use it to build your orchestration graph. You can read more about Rune CLI tools in our dev website - hotg.dev
Currently, we do not have support for models with multiple inputs and outputs, however, it is something that is being worked on for our next release. This is an exciting feature as multiple input/outputs are something which Natural Language Processing (NLP) models (our next release after audio models) also require.
Building Your Own Rune
For kinesthetic learners like me, rather than understanding concepts in the abstract, Runes will make a lot more sense if I can make one myself. We have a multi-speech model which can detect the words "up", "down", "left", and "right". Let's convert that into a rune!
Please note that to follow along on your device, you will need to install the rune-cli tool.
Clone our test-runes Github repository.
$ git clone <https://github.com/hotg-ai/test-runes.git>Enter the multi-speech subdirectory
$ cd test-runes/audio/multispeech/
There are 3 main components in the multi-speech subdirectory
Runefile.yml - Contains the pipeline which is compiled to a rune
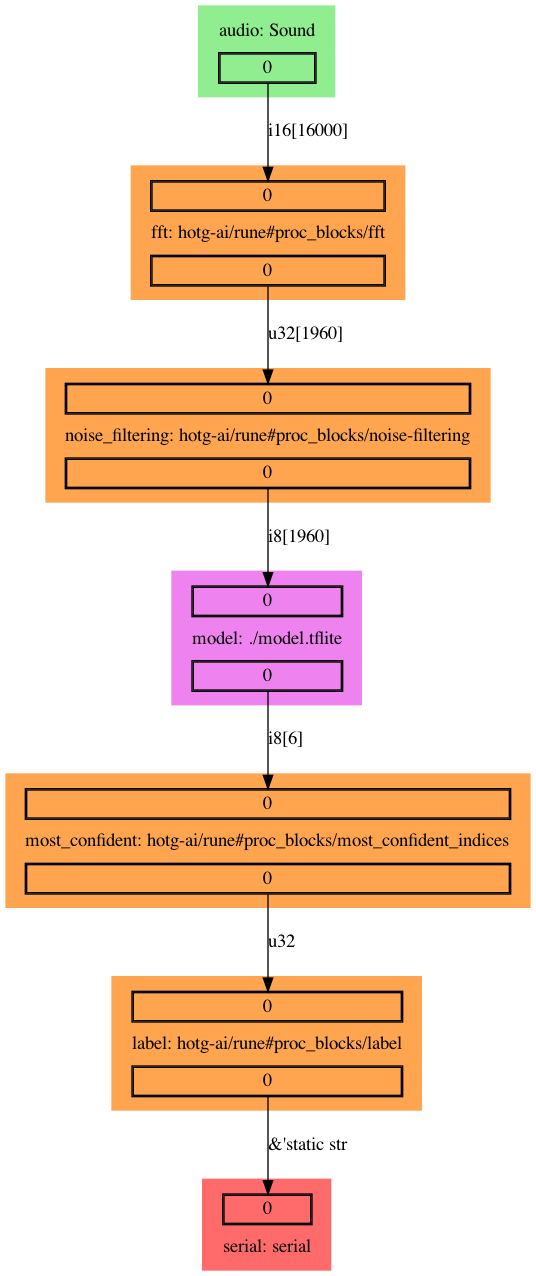
A visualization of the Rune pipeline written in Runefile.yml and visualized here below: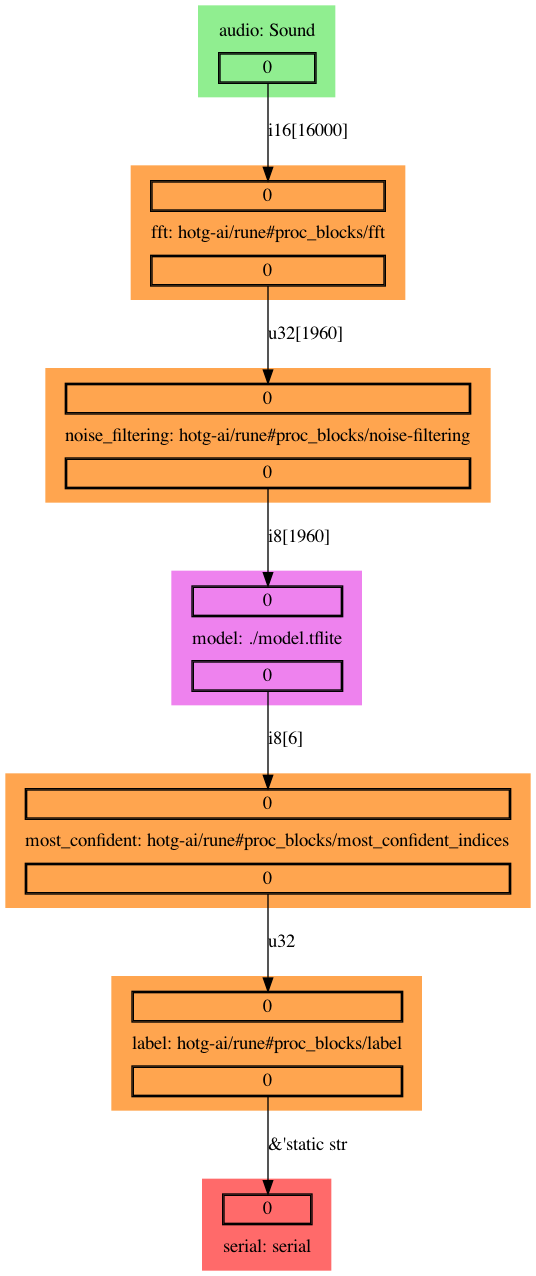
This is a straightforward workflow. The audio data is being pre-processed by a Fourier Fast Transform, and a noise filter. It is then fed into the model which outputs a confidence vector. There are 2 post-processing steps applied to reduce and map the confidence vector. The data is then sent to the host device in JSON format.
model.tflite - Contains the multi-speech TFLite model
assets/ - Contains an audio file aud_up.wav which has a 1 second recording of the word "up"
Build the rune
$ rune build Runfile.ymlRune should build successfully, you should see a file called multispeech.rune. Let's test it against the audio file to see if it works.
$ rune run multispeech.rune --capability=sound:assets/aud_up.wav
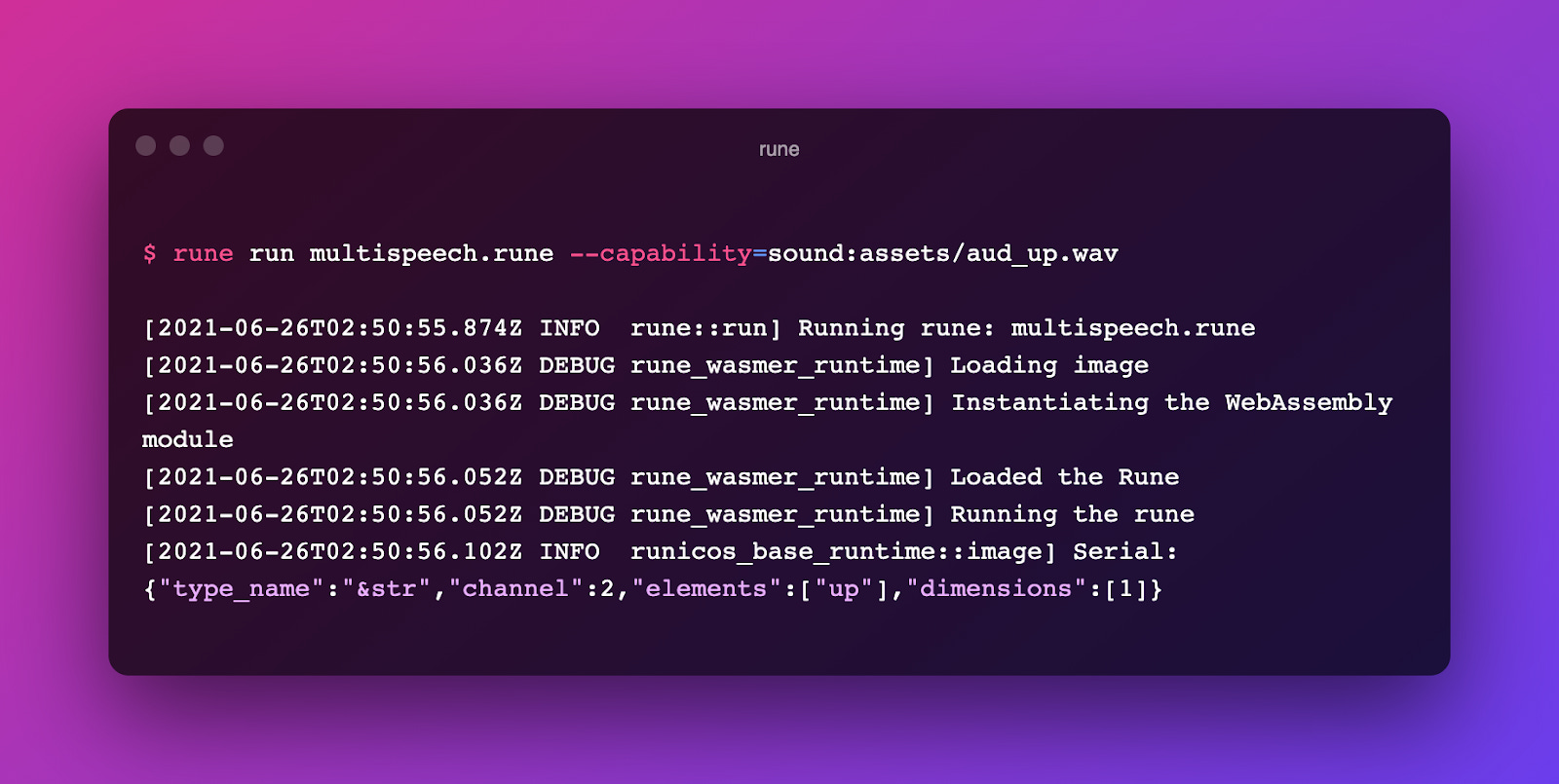
As you can see in the last line of the output, the "element" key in the JSON output is matched with the "up" value. Our Rune worked as intended!
Exciting Use of Runes
Running the rune from a terminal against a pre-recorded input may not seem extremely interesting, so we decided to do what any sane programmer would - Integrate it with a game!
We created a flutter plugin to help you quickly deploy the rune into a mobile app. Here's a quick video of the example 2048 game we created which uses the multi-speech rune to control the game movement.
Think of how adding voice based controls for your apps might become a game changer. Hint hint: “Hey Spotify”, “Hey Siri”.
You can do that with Rune today - drop us a note at community@hotg.ai and we are happy to help you.
This is an extremely exciting use case which has a simple rune to detect 4 words. As we grow our repository of runes and build support for more models, we can elevate mobile applications and other devices to the next level by leveraging ML, further empowering developers with easy to implement tools.
In our coming releases, we are planning on launching event extraction, speech synthesis and audio embedding runes. Stay in the loop with our releases and developer discussions by joining our discord channel!
Follow us on our socials:
Twitter @hotg_ai and @hammer_otg | LinkedIn | Discord | Discourse