


Edge-Cloud Collaboration
Can AI models benefit from distributed edge-cloud collaboration?
In the previous posts we introduced our tool, Rune and showed how easy it is to deploy machine learning models on smart phones. We also shared how this fits into our larger vision on distributed applications. In this post, we go one step further and show how edge and cloud models can benefit from collaboration.
Edge vs Cloud Deployments
When developers are bringing their machine learning model into production, they typically have to make a choice between running the model on an edge device or in the cloud. Both approaches have their advantages and disadvantages. Cloud deployment is typically much easier; there are plenty of compute resources available and energy consumption is typically less of an issue. The disadvantage, however, is that all data needs to be transferred to the cloud. This might cause an unacceptable latency and also means that the application depends on a reliable network connection to function correctly. Edge computing provides an answer to these questions, by deploying the machine learning model to a device close to the sensor (no data ever leaves the device). Edge devices are however very constrained in compute resources which makes it difficult to deploy large machine models on them. Depending on the application, the developer has to decide which of the two is the best choice. In this post, we introduce a third option which illustrates how edge and cloud computing might work together to provide the best user experience.
Edge-cloud collaboration
Let’s take a look at a very common example of image classification. People typically train their model on the imagenet dataset. The resulting model can recognize a thousand different classes including different dog breeds, cars, planes and various types of objects. As explained in the previous section, the developer then might want to deploy the model to an edge device. He might even look into quantization or pruning techniques and while these will improve the efficiency of the model, the model might still be too large to run comfortably on a low end device. Instead, we propose to use the locality principle of edge computing. With edge computing, we process the data close to the sensor. Do we really need a model that can distinguish between elephants, planes, flowers and laptops? How likely is it for the device to be in an area where it will see both elephants and kitchen appliances? Do we really need to distinguish a hundred different dog breeds? In the example below, we designed a very small model to recognize whether an image shows a dog or something else. This tiny model can easily be deployed on an edge device and can quickly recognize if an image shows the class we are looking for (in this case dogs). We also deployed a pre-trained classification model in the cloud, this model is much larger and can recognize a thousand different classes, including different dog breeds. We first pass the image through the edge model which predicts whether the image shows a dog or not.
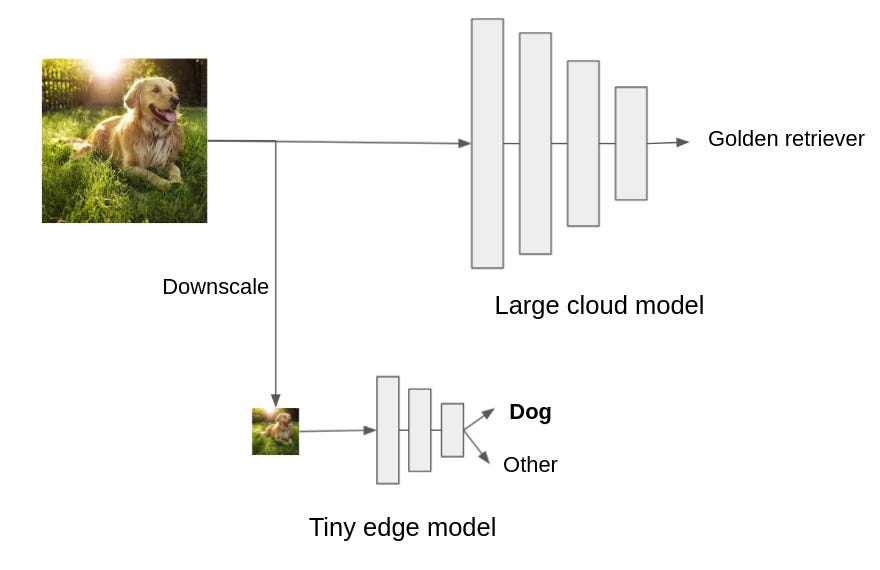
While the edge model is processing the image, we can also transmit the image to the cloud to obtain a more detailed classification. While this is a very basic example of how cloud and edge models can collaborate, it has several advantages compared to a purely edge or cloud deployment. Because the edge model is very small, we are able to deploy it on a low end device and can obtain a first prediction very fast. We can then immediately act upon this prediction or wait until the cloud returns a more fine grained result. We could even use the edge model as a switch, if we are only interested in detecting different dog breeds, we should only transmit images that show dogs to the cloud. The edge model can perform this filter step, saving bandwidth and energy.
How does Rune help us ?
Distributed Rune
Rune allows you to package your ML model into a portable container that can be deployed on the cloud or on an edge device. In future versions, Rune will also support calling remote Runes by transmitting input data or intermediate feature representations over the network. This will make it easy to implement these kinds of distributed environments. Even though this was the most basic example of a distributed edge-cloud pipeline, we believe that a lot of applications could benefit from similar approaches and Rune will be the tool to build them.
The expressive power of Rune allows us to define the computation declaratively, which we means we can wire up the routing of processing from one point to another on the device. This capability allows us to route certain parts of the output (example model output, or model embeddings, or proc_block outputs etc) to be routed to a device running another Rune - it could be Rune running on a cloud, or could as well be Rune running on an another device near the first device.
We talk about resiliency when building TinyML applications and distributed Rune is the cute idea that we plan to exploit to bring resiliency to TinyML applications.
We hope you are as excited about the possibilities of edge-cloud collaboration and the future of distributed edge computing has to offer. Do you want to contribute to/use Rune? Email us at community@hotg.ai to be our open source developer. And most of all, we’re going to have a ton of fun! The latter is all that matters, right?
Some ways you can contribute:
Making rune build natively on all platforms
Creating processing blocks for various models and scenarios
Adding support for additional hardware and platforms
Building TinyML apps using rune :)
You can read more about it here: https://hotg.dev/docs/contribute