

We have previously written about our ideas and vision of what tinyML Ops means, and why we are pursuing that at HOTG.
A quick refresher on TinyML Ops:
With tinyML we can simply leverage a “rough” cloud model and improve it with rapid prototyping. TinyML prototyping is a pain today due to the deployment friction. In prototyping, we would want to simulate signals and change application or update the models and deploy them back seamlessly. We can do this by exploiting the principle of locality to improve ML performance
TinyML Ops is a set of tools to solve this.
Processing Blocks in a Machine Learning Workflow
Last time, we discussed how you may want to calibrate a prebuilt model for new environments. A refresher quip from that post:
In this post, we look at the creation of an example processing block in a real machine learning workflow. The application we focus on is keyword detection, and the model combines a spectrogram computer with a CNN. The original spectrogram computer is implemented in C-code, and we translate it into Rune processing blocks for deployment as Runes on tiny edge devices.
The tinyML the environment where the model runs, acts as a filter for data we need to improve the model.
When deployed to new environments or devices, ML models may need to be recalibrated. Recalibration can be done to fit the output of a processing block or to fit the data distribution of a user/behavior not represented in the model’s initial training set.
In this post, we focus on the same example of an audio model, and we calibrate that model to a Rust version of a TensorFlow spectrogram processing block. The audio model was trained to recognize four keywords:
Up
Down
Left
Right
Model performance before calibration
Before calibration, the model accuracy, using a spectrogram computer processing block it was not trained with, is 22.7%, and the confusion matrix between ground truth and predicted labels is:

The accuracies of recognizing individual commands are:
“Up” 50%
“Down” 0%
“Left” 51%
“Right” 2%.
This is due to a significant mismatch between the original spectrogram computer used when training the model, and the processing block used at model deployment. In order for the model to perform reliably at deployment, the same preprocessing has to be applied during deployment as during training, and the training dataset has to be representative of the data encountered during deployment.
Performing calibration
The model calibration is performed by retraining the model on spectrograms pre-computed for each of the sound clips in the common speech dataset using the Rust FFT processing block, callable from Python.
Here is the code for the specific processing block:
from rune_py import Fft, NoiseFiltering
def compute_rune_spec(data):
""" Compute the spectrogram using the Rune proc block equivalent to the TensorFlow spectrogram computer """
fft = Fft()
noise_filtering = NoiseFiltering()
fft.sample_rate = 16000
noise_filtering.smoothing_bits = 10
noise_filtering.even_smoothing = 0.025
noise_filtering.odd_smoothing = 0.06
noise_filtering.min_signal_remaining = 0.05
noise_filtering.strength = 0.95
noise_filtering.offset = 80.0
noise_filtering.gain_bits = 21
rune_spec = noise_filtering(fft(data))
return rune_specThen, the model is trained and tested on those spectrograms.
Model performance after calibration
After calibration, the model accuracy is 80.6%, and the confusion matrix is:
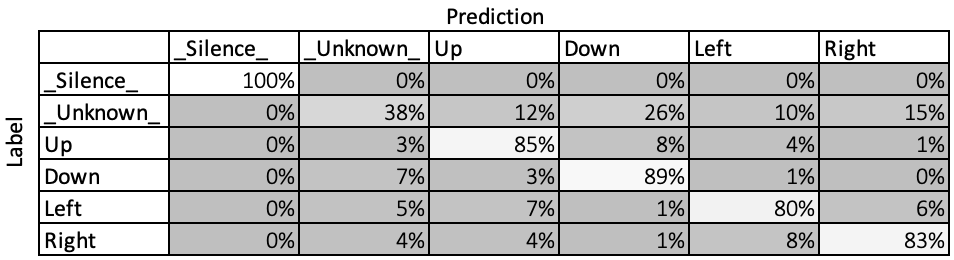
The accuracies of recognizing individual commands are:
“Up” 85%
“Down” 89%
“Left” 80%
“Right” 83%
This is clearly a significant improvement over the initial model performance that had a mismatched processing block!
The key takeaway here is the expressive power and composability of building Runes with processing blocks. This is how it supports machine learning ops (ML Ops) for edge models which we call tinyML Ops :)
One more thing
Calibration to different languages and accents
Another scenario where an audio model might need to be calibrated is in case the language or accent of the speaker differs during model training and deployment.
We calibrated our model to recognize commands in Estonian, by using the phrases “üles”, “alla”, “vasak”, “parem” in place of “up”, “down”, “left”, “right”, achieving 75% accuracy with just 10 phrases recorded per command. This is the key idea behind exploiting the principle of locality to improve ML performance.
It is on the edges of the tinyverse we find things that are unique, more personal, and a degree closer to the truth. With Rune and tinyML Ops we are several orders of computes closer to this truth.
At HOTG, we build tools to make calibration of models easy for both different data distributions and processing blocks. This will enable audio and other models adapted to different users, environments, and processing blocks.
Soon you will be able to build compelling apps to federate intelligence to the edges as well - we are very close to our open source launch.
Look out for our upcoming post on this!